Conform#
Matières :
Aperçu#
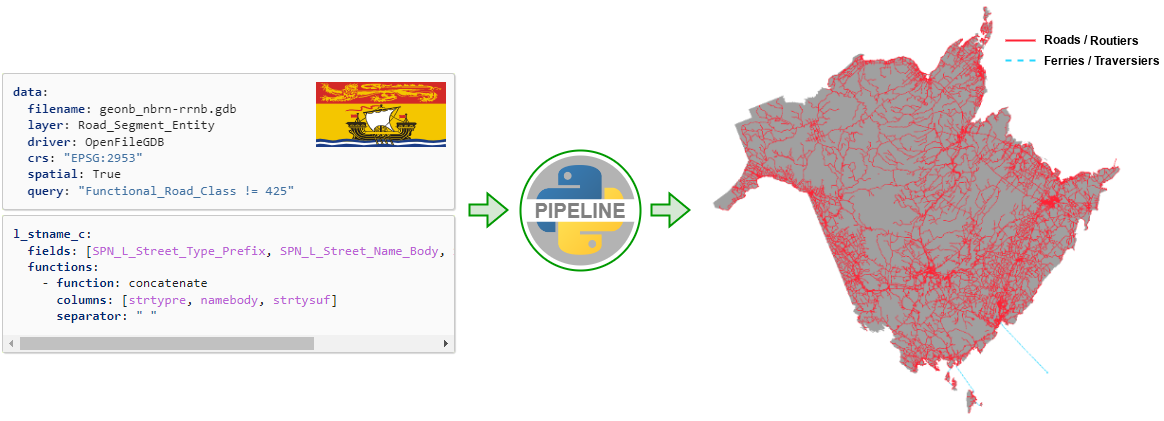
Figure 1 : Exemple de pipeline.#
Le processus conform utilise un ou plusieurs fichiers de configuration YAML (.yaml) pour définir le mappage des
données source vers le schéma RRN.
Le schéma RRN est défini dans Catalogue d’entités.
Idéalement, les données sources adhéreraient au schéma RRN et auraient un mappage de champ direct (1 : 1). Malheureusement, cela ne reflète pas la réalité. Par conséquent, pour permettre l’intégration d’autant de sources de données que possible, un certain nombre de fonctions ont été développées pour manipuler les données sources en vue de leur intégration dans le modèle de données RRN.
- Correspondance des attributs
Le processus d’intégration des données sources dans le modèle de données RRN.
- Clé
Attribut individuel d’un fichier
YAML. Les fichiersYAMLsont constitués de paires clé-valeur similaires aux dictionnaires Python.- YAML
Langage de sérialisation des données couramment utilisé pour les fichiers de configuration.
Aperçu des configurations#
Répertoires#
Répertoire racine#
Le répertoire root pour tous les fichiers de configuration est : nrn-rrn/src/conform/sources.
Sous-répertoires#
Chaque fichier de configuration doit résider dans un sous-répertoire de root, où le nom du sous-répertoire est
l’abréviation provinciale/territoriale de la source de données. Les abréviations de source acceptées sont les
suivantes :
Abréviation |
Source (Province / Territoire) |
|---|---|
ab |
Alberta |
bc |
Colombie-Britannique |
mb |
Manitoba |
nb |
Nouveau-Brunswick |
nl |
Terre-Neuve et Labrador |
ns |
Nouvelle-Écosse |
nt |
Territoires du Nord-Ouest |
nu |
Nunavut |
on |
Ontario |
pe |
Île-du-Prince-Édouard |
qc |
Québec |
sk |
Saskatchewan |
yt |
Yukon |
Fichiers#
Noms de fichiers#
Les noms de fichiers de configuration individuels n’ont pas d’importance, tant qu’ils ont l’extension .yaml requise.
Intégrité du nom de fichier#
Chaque jeu de données source (fichier ou couche) doit être défini dans son propre fichier de configuration. De même, chaque jeu de données RRN ne doit être défini que dans un seul fichier de configuration par sous-répertoire source, sinon les résultats seront écrasés par les fichiers de configuration suivants qui correspondent au même jeu de données RRN.
Structure#
Structure générique :
src
├── conform
│ ├── sources
│ │ ├── <source abbreviation>
│ │ │ ├── <configuration file name>.yaml
│ │ │ ├── <configuration file name>.yaml
│ │ │ ...
Structure spécifique (source : Nouveau-Brunswick) :
src
├── conform
│ ├── sources
│ │ ├── nb
│ │ │ ├── geonb_nbrn-rrnb_ferry-traversier.yaml
│ │ │ └── geonb_nbrn-rrnb_road-route.yaml
Contenu de la configuration#
Les fichiers de configuration se composent de 3 composants principaux (sections) :
- Métadonnées
Métadonnées de la source.
- Data
Fichier source et propriétés de la couche.
- Conform
Définit la correspondance des attributs.
Métadonnées#
Les composants de métadonnées définissent tous les détails pertinents sur les données source. Aucune clé de métadonnées n’est obligatoire, mais il est fortement encouragé de remplir autant de clés de métadonnées que possible car il s’agit de la principale référence utilisée pour contextualiser et se référer à la source de données, si jamais nécessaire.
Structure#
Structure générique :
coverage:
country:
province:
ISO3166:
alpha2:
country:
subdivision:
website:
update_frequency:
license:
url:
text:
language:
Structure spécifique (source : Nouveau-Brunswick) :
coverage:
country: ca
province: nb
ISO3166:
alpha2: CA-NB
country: Canada
subdivision: New Brunswick
website: https://geonb-t.snb.ca/downloads/nbrn/geonb_nbrn-rrnb_orig.zip
update_frequency: weekly
license:
url: http://geonb.snb.ca/documents/license/geonb-odl_en.pdf
text: GeoNB Open Data License
language: en
Data#
Les composants de données (« data » en anglais) définissent les propriétés du fichier source et de la couche pertinentes pour la construction d’un ensemble de données RRN.
Clés obligatoires :
- filename
Nom du fichier source, y compris l’extension.
- driver
Nom du pilote vectoriel
OGR(voir les détails complets du pilote).- crs
Chaîne d’autorité du système de référence de coordonnées.
- spatial
Drapeau pour indiquer si la source est spatiale.
Clés facultatives :
- layer
Nom de couche pour les fichiers contenant des couches de données.
- query
Requête utilisée pour filtrer les enregistrements de source de données.
Structure#
Structure générique :
data:
filename:
layer:
driver:
crs:
spatial:
query:
Structure spécifique (source : Nouveau-Brunswick) :
data:
filename: geonb_nbrn-rrnb.gdb
layer: Road_Segment_Entity
driver: OpenFileGDB
crs: "EPSG:2953"
spatial: True
query: "Functional_Road_Class != 425"
Conform#
Les composants conformes (« conform » en anglais) définissent la correspondance d’attribut entre les données source et le schéma RRN. La correspondance d’attribut peut être soit directe (l’attribut source correspond directement à un attribut de données RRN) soit utiliser une série de fonctions.
Structure#
Structure générique :
conform:
<jeu de données RRN>:
<attribut de jeu de données RRN>: <correspondance d'attribut>
...
...
Aucune correspondance d’attribut#
Les clés des ensembles de données ou des attributs RRN sans aucune correspondance d’attribut source peuvent être exclues du fichier de configuration ou simplement laissées vides.
Correspondance d’attribut directe#
Les attributs RRN avec une correspondance d’attribut directe de la source peuvent être renseignés avec une valeur littérale ou un nom d’attribut. La valeur spécifiée est déterminée comme étant un nom d’attribut s’il existe dans l’ensemble d’attributs du fichier/couche source.
Exemple :
accuracy: Element_Planimetric_Accuracy
Fonctions de correspondance des attributs#
Pour définir une fonction de correspondance d’attributs, les clés suivantes doivent être utilisées :
fieldsUn nom d’attribut ou une liste de noms d’attributs du fichier/couche source.
functionsUne liste de noms de fonction et de paramètres spécifiques à la fonction. La première clé de chaque fonction répertoriée doit être
functionsuivie du nom de la fonction.
Les fonctions de correspondance d’attributs multiples sont appelées chains et le processus en tant que
chaining. Pour les chains, la sortie de chaque fonction est l’entrée de la fonction suivante.
Structure#
Structure générique :
<attribut de jeu de données RRN>:
fields: <attribut source> or [<attribut source>, ...]
functions:
- function: <nom de la fonction>
<nom du paramètre de fonction>: <valeur du paramètre de fonction>
...
- ...
Fonction: apply_domain#
Paramètre |
Valeur |
|---|---|
table |
Nom du jeu de données RRN. |
field |
Nom d’attribut RRN. |
default |
Valeur par défaut à utiliser en cas d’erreur. |
Exemple :
dirprefix:
fields: SPN_R_Directional_Prefix
functions:
- function: apply_domain
table: strplaname
field: dirprefix
default: None
Fonction: concatenate#
Paramètre |
Valeur |
|---|---|
columns |
Liste des noms attribués aux colonnes de données lorsqu’elles sont décompressées dans la fonction. |
separator |
Chaîne de délimiteur utilisée pour joindre les valeurs, par défaut = |
Exemple :
l_stname_c:
fields: [SPN_L_Street_Type_Prefix, SPN_L_Street_Name_Body, SPN_L_Street_Type_Suffix]
functions:
- function: concatenate
columns: [strtypre, namebody, strtysuf]
separator: " "
Fonction: direct#
Paramètre |
Valeur |
|---|---|
cast_type |
Nom de chaîne d’une classe de type Python à convertir, par défaut = |
Exemple :
l_hnumf:
fields: First_House_Number_L
functions:
- function: direct
cast_type: int
Fonction: map_values#
Paramètre |
Valeur |
|---|---|
lookup |
Dictionnaire des correspondances de valeurs. |
case_sensitive |
Indicateur indiquant si le dictionnaire de recherche est sensible à la casse, valeur par défaut = False. |
Exemple :
provider:
fields: Element_Provider
functions:
- function: map_values
lookup:
1: Other
2: Federal
3: Provincial / Territorial
4: Municipal
405: Provincial / Territorial
406: Provincial / Territorial
409: Municipal
412: Other
Fonction: query_assign#
Paramètre |
Valeur |
|---|---|
columns |
Liste des noms attribués aux colonnes de données lorsqu’elles sont décompressées dans la fonction. |
lookup |
Dictionnaire des correspondances requête-valeur où la valeur est un dictionnaire imbriqué composé de clés :
|
engine |
Le moteur utilisé pour traiter l’expression, par défaut = |
**kwargs |
Arguments de mots clés facultatifs transmis à |
Exemple :
provider:
fields: AGENCY_NAME
functions:
- function: query_assign
columns: provider
lookup:
provider.str.lower().str.contains('city of |county of |municipality of ', na=False, regex=True):
value: Municipal
type: string
provider.str.lower().isin(['ministry of natural resources and forestry', 'ministry of health']):
value: Provincial
type: string
provider.str.lower().isin(['elections and statistics canada', 'nrcan']):
value: Federal
type: string
provider.str.lower() == 'waabnoong bemjiwang association of first nations':
value: Other
type: string
engine: python
Fonction: regex_find#
Paramètre |
Valeur |
|---|---|
pattern |
Une expression régulière compilable. |
match_index |
Index de position de la correspondance souhaitée renvoyée par l’expression régulière. |
group_index |
Index de position du groupe de capture souhaité dans la correspondance souhaitée (voir
|
strip_result |
La valeur extraite sera supprimée de la valeur d’origine, plutôt que renvoyée, valeur par défaut = False. |
sub_inplace |
Arguments de mots clés facultatifs passés à |
Exemple :
rtnumber1:
fields: PHA_ROADNA
functions:
- function: regex_find
pattern: "\\b([1-9][0-9]*)\\b"
match_index: 0
group_index: 0
Fonction: regex_sub#
Paramètre |
Valeur |
|---|---|
**kwargs |
Mots-clés passés à |
Exemple :
rtename1en:
fields: PHA_ROADNA
functions:
- function: regex_sub
pattern: "\\b(No. [1-9][0-9]*)\\b"
repl: ""
Fonctions de correspondance des attributs - Touches spéciales#
Processus séparément#
process_separately est une clé spéciale qui peut être incluse avec les clés de correspondance d’attributs
obligatoires (fields et functions). Lorsque process_separately: True, plusieurs attributs source peuvent
être mis en correspondance avec des fonctions de correspondance d’attributs qui n’acceptent normalement qu’un seul
attribut source.
Le but de cette clé spéciale est de permettre à plusieurs attributs de source d’être mis en correspondance avec le même attribut RRN lorsque la correspondance d’attribut n’est pas directe.
Les valeurs de sortie de process_separately seront imbriquées.
Exemple :
placename:
fields: [SPN_L_Place_Name, SPN_R_Place_Name]
process_separately: True
functions:
- function: map_values
lookup:
1: Aboujagane
2: Acadie Siding
3: Acadieville
...
Itérer les colonnes#
iterate_cols est une clé spéciale qui peut être incluse avec les clés spécifiques à chaque fonction.
iterate_cols accepte une liste d’entiers représentant l’index de position des attributs source listés par
fields. Lorsqu’ils sont renseignés, seuls les attributs source indiqués par iterate_cols sont traités par la
fonction de correspondance d’attributs définie. Les attributs source non spécifiés par iterate_cols conserveront
leurs valeurs.
Le but de cette clé spéciale est de permettre une chain où seuls certains attributs source nécessitent un
traitement supplémentaire par certaines fonctions de correspondance d’attributs.
Exemple :
l_stname_c:
fields: [L_Direction_Prefix, L_Type_Prefix, L_Article, L_Name_Body, L_Type_Suffix, L_Direction_Suffix]
functions:
- function: map_values
iterate_cols: [0, 5]
lookup:
1: North
2: South
3: East
4: West
- function: concatenate
columns: [dirprefix, strtypre, starticle, namebody, strtysuf, dirsuffix]
separator: " "
Domaines d’attributs#
Lors de l’utilisation d’une fonction de correspondance d’attribut qui accepte une expression régulière, le mot-clé
domain_<nom du jeu de données>_<nom d'attribut> peut être utilisé pour insérer les valeurs de domaine restreint de
tout attribut RRN dans l’expression, séparées par le ou opérateur |.
Exemple (brutes) :
dirprefix:
fields: L_Directional_Prefix
functions:
- function: regex_find
pattern: "\\b(domain_strplaname_dirprefix)\\b(?!$)"
match_index: 0
group_index: 0
La définition de correspondance d’attribut ci-dessus sera convertie en :
dirprefix:
fields: L_Directional_Prefix
functions:
- function: regex_find
pattern: "\\b(None|North|South|East|West|Northwest|Northeast|Southwest|Southeast|Central|Centre)\\b(?!$)"
match_index: 0
group_index: 0
Notez
Seule une liste condensée de valeurs de domaine est affichée afin d’économiser de l’espace.
Sortie imbriquée#
Exclusif à l’ensemble de données RRN strplaname, après le processus complet de correspondance des attributs, si des
attributs de sortie sont renseignés par des valeurs imbriquées, telles qu’une liste, tous les enregistrements de cet
ensemble de données seront dupliqués de sorte que le premier emboîté la valeur de chaque attribut imbriqué devient la
valeur d’attribut réelle pour la première instance dupliquée et la deuxième valeur imbriquée de chaque attribut
imbriqué devient la valeur d’attribut réelle pour la deuxième instance dupliquée.
Cette logique exclusive pour l’ensemble de données RRN strplaname permet d’attribuer des attributs avec une
représentation à gauche et à droite à un seul attribut RRN.
Exemple :
placename: [SPN_L_Place_Name, SPN_R_Place_Name]
Segmentation des adresses#
Le processus de conform du RRN comprend un processus spécial pour segmenter les adresses contenues dans un ensemble
de données de Points en plages. Pour la segmentation des adresses, aucune clé conform n’existe et, à la place, une
clé supplémentaire segment est incluse dans la clé data et a la structure brute suivante :
segment:
address_fields:
street:
number:
suffix:
address_join_field:
fields:
separator:
roadseg_join_field:
fields:
separator:
Cette structure de données contient 3 clés obligatoires :
address_fieldsDéfinit comment extraire les composants d’adresse des données source. Seuls les composants d’attribut de base
street(nom de la rue),number(numéro d’adresse) etsuffix(suffixe du numéro d’adresse) sont acceptés. Les valeurs acceptables sont :a) Un nom d’attribut ou,b) Un dictionnaireregex_subcomposé des clésfield,pattern, etreplqui sera passé àre.sub().c) Un dictionnaireconcatenatecomposé de clés définissant la concaténation des attributs :fields: Une liste d’attributs.separator: Un délimiteur utilisé pour concaténer les attributs.address_join_fieldAttribut de la source d’adresse utilisée pour joindre l’ensemble de données RRN
roadseg. Les valeurs acceptables sont :a) Un nom d’attribut ou,b) Un dictionnaire composé de clés définissant la concaténation des attributs source d’adresse :fields: Une liste d’attributs de source d’adresse.separator: Un délimiteur utilisé pour concaténer les attributs.roadseg_join_fieldAttribut de l’ensemble de données RRN
roadsegutilisé pour se joindre à la source d’adresse. Les valeurs acceptables sont :a) Un nom d’attribut ou,b) Un dictionnaire composé de clés définissant la concaténation des attributs du jeu de données RRNroadseg:fields: Une liste des attributsroadsegde l’ensemble de données RRN.separator: Un délimiteur utilisé pour concaténer les attributs.
Sortir#
L’ensemble de données de sortie contiendra tous les attributs d’adressage de l’ensemble de données RRN addrange et
utilisera les attributs fournis (address_join_field et roadseg_join_field) à joindre à l’ensemble de données
source correspondant à l’ensemble de données RRN roadseg. Par conséquent, tous les attributs d’adressage de
addrange peuvent être utilisés dans le fichier de configuration pour l’ensemble de données RRN roadseg
puisqu’ils existeront sur l’ensemble de données source avant l’exécution du processus de correspondance des attributs.
Exemples#
Exemple simple (source : Île-du-Prince-Édouard) :
segment:
address_fields:
street: street_nm
number: street_no
suffix:
address_join_field: street_nm
roadseg_join_field: street_nm
Exemple avancé (source : Yukon) :
segment:
address_fields:
street: street
number:
field: number
regex_sub:
pattern: "[^\\d]"
repl: ""
suffix:
field: number
regex_sub:
pattern: "\\d+"
repl: ""
address_join_field: street
roadseg_join_field:
fields: [dirprefix, strtypre, namebody, strtysuf, dirsuffix]
separator: " "