Conform#
Contents:
Overview#
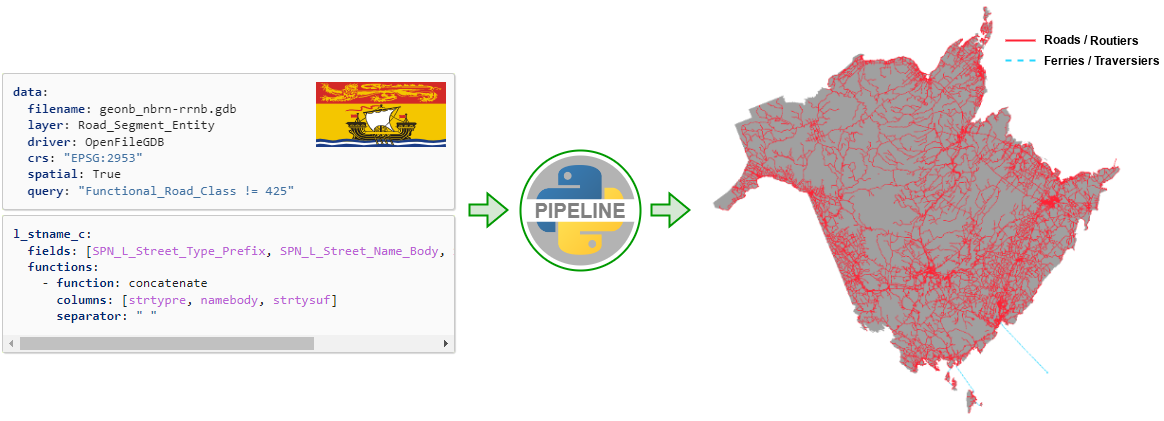
Figure 1: Pipeline example.#
The conform process uses one or more YAML (.yaml) configuration file(s) to define the mapping of source data to
the NRN schema.
The NRN schema is defined in Feature Catalogue.
Ideally, source data would adhere to the NRN schema and have direct (1:1) field mapping. Unfortunately, this does not reflect reality. Therefore, to accommodate the integration of as many data sources as possible, a number of functions have been developed to manipulate source data for integration into the NRN data model.
- Field Mapping
The process of source data integration into the NRN data model.
- Key
Individual attribute of a
YAMLfile.YAMLfiles consist of key-value pairs similar to Python dictionaries.- YAML
Data serialization language commonly used for configuration files.
Configuration Overview#
Directories#
Root Directory#
The root directory for all configuration files is: nrn-rrn/src/conform/sources.
Subdirectories#
Each configuration file must reside within a subdirectory of root, where the subdirectory name is the provincial /
territorial abbreviation of the data source. Accepted source abbreviations are as follows:
Abbreviation |
Source (Province / Territory) |
|---|---|
ab |
Alberta |
bc |
British Columbia |
mb |
Manitoba |
nb |
New Brunswick |
nl |
Newfoundland and Labrador |
ns |
Nova Scotia |
nt |
Northwest Territories |
nu |
Nunavut |
on |
Ontario |
pe |
Prince Edward Island |
qc |
Quebec |
sk |
Saskatchewan |
yt |
Yukon |
Files#
File Names#
Individual configuration file names do not matter, so long as they have the required .yaml extension.
File Name Integrity#
Each source dataset (file or layer) must be defined within its own configuration file. Similarly, each NRN dataset must only be defined in a single configuration file per source subdirectory, otherwise the results will be overwritten by subsequent configuration files which map to the same NRN dataset.
Structure#
Generic structure:
src
├── conform
│ ├── sources
│ │ ├── <source abbreviation>
│ │ │ ├── <configuration file name>.yaml
│ │ │ ├── <configuration file name>.yaml
│ │ │ ...
Specific structure (source: New Brunswick):
src
├── conform
│ ├── sources
│ │ ├── nb
│ │ │ ├── geonb_nbrn-rrnb_ferry-traversier.yaml
│ │ │ └── geonb_nbrn-rrnb_road-route.yaml
Configuration Content#
Configuration files consist of 3 main components (sections):
- Metadata
Source metadata.
- Data
Source file and layer properties.
- Conform
Field mapping definitions.
Metadata#
The metadata components define all relevant details about the source data. No metadata keys are mandatory but it is strongly encouraged to populate as many metadata keys as possible as it is the primary reference used to contextualize and refer back to the data source, if ever required.
Structure#
Generic structure:
coverage:
country:
province:
ISO3166:
alpha2:
country:
subdivision:
website:
update_frequency:
license:
url:
text:
language:
Specific structure (source: New Brunswick):
coverage:
country: ca
province: nb
ISO3166:
alpha2: CA-NB
country: Canada
subdivision: New Brunswick
website: https://geonb-t.snb.ca/downloads/nbrn/geonb_nbrn-rrnb_orig.zip
update_frequency: weekly
license:
url: http://geonb.snb.ca/documents/license/geonb-odl_en.pdf
text: GeoNB Open Data License
language: en
Data#
The data components define the properties of the source file and layer relevant to constructing an NRN dataset.
Mandatory keys:
- filename
Name of the source file, including the extension.
- driver
OGRvector driver name (see complete driver details).- crs
Coordinate Reference System authority string.
- spatial
Flag to indicate if the source is spatial.
Optional keys:
- layer
Layer name for files containing data layers.
- query
Query used to filter data source records.
Structure#
Generic structure:
data:
filename:
layer:
driver:
crs:
spatial:
query:
Specific structure (source: New Brunswick):
data:
filename: geonb_nbrn-rrnb.gdb
layer: Road_Segment_Entity
driver: OpenFileGDB
crs: "EPSG:2953"
spatial: True
query: "Functional_Road_Class != 425"
Conform#
The conform components define the field mapping between the source data and NRN schema. Field mapping can be either direct (source attribute directly maps to an NRN data attribute) or make use of a series of functions.
Structure#
Generic structure:
conform:
<NRN dataset>:
<NRN dataset attribute>: <field mapping>
...
...
No Field Mapping#
Keys for NRN datasets or attributes without any source field mapping can be excluded from the configuration file or simply left empty.
Direct Field Mapping#
NRN attributes with a direct field mapping from the source can be populated with a literal value or attribute name. The specified value is determined to be an attribute name if it exists in the set of attributes for the source file / layer.
Example:
accuracy: Element_Planimetric_Accuracy
Field Mapping Functions#
To define a field mapping function, the following keys must be used:
fieldsAn attribute name or list of attribute names of the source file / layer.
functionsA list of function names and function-specific parameters. The first key in each listed function must be
functionfollowed by the function name.
Multiple field mapping functions are referred to as chains and the process as chaining. For chains, the
output of each function is the input to the next function.
Structure#
Generic structure:
<NRN dataset attribute>:
fields: <source attribute> or [<source attribute>, ...]
functions:
- function: <function name>
<function parameter name>: <function parameter value>
...
- ...
Function: apply_domain#
Parameter |
Value |
|---|---|
table |
NRN dataset name. |
field |
NRN attribute name. |
default |
Default value to be used if an error is encountered. |
Example:
dirprefix:
fields: SPN_R_Directional_Prefix
functions:
- function: apply_domain
table: strplaname
field: dirprefix
default: None
Function: concatenate#
Parameter |
Value |
|---|---|
columns |
List of names assigned to the data columns when unpacked within the function. |
separator |
Delimiter string used to join the values, default = |
Example:
l_stname_c:
fields: [SPN_L_Street_Type_Prefix, SPN_L_Street_Name_Body, SPN_L_Street_Type_Suffix]
functions:
- function: concatenate
columns: [strtypre, namebody, strtysuf]
separator: " "
Function: direct#
Parameter |
Value |
|---|---|
cast_type |
String name of a Python type class to be casted to, default = |
Example:
l_hnumf:
fields: First_House_Number_L
functions:
- function: direct
cast_type: int
Function: map_values#
Parameter |
Value |
|---|---|
lookup |
Dictionary of value mappings. |
case_sensitive |
Flag indicating if the lookup dictionary is case sensitive, default = |
Example:
provider:
fields: Element_Provider
functions:
- function: map_values
lookup:
1: Other
2: Federal
3: Provincial / Territorial
4: Municipal
405: Provincial / Territorial
406: Provincial / Territorial
409: Municipal
412: Other
Function: query_assign#
Parameter |
Value |
|---|---|
columns |
List of names assigned to the data columns when unpacked within the function. |
lookup |
Dictionary of query-value mappings where the value is a nested dictionary consisting of keys:
|
engine |
The engine used to process the expression, default = |
**kwargs |
Optional keyword arguments passed to |
Example:
provider:
fields: AGENCY_NAME
functions:
- function: query_assign
columns: provider
lookup:
provider.str.lower().str.contains('city of |county of |municipality of ', na=False, regex=True):
value: Municipal
type: string
provider.str.lower().isin(['ministry of natural resources and forestry', 'ministry of health']):
value: Provincial
type: string
provider.str.lower().isin(['elections and statistics canada', 'nrcan']):
value: Federal
type: string
provider.str.lower() == 'waabnoong bemjiwang association of first nations':
value: Other
type: string
engine: python
Function: regex_find#
Parameter |
Value |
|---|---|
pattern |
A compilable regular expression. |
match_index |
Positional index of the desired match returned by the regular expression. |
group_index |
Positional index of the desired capturing group within the desired match (see |
strip_result |
The extracted value will be stripped from the original value, rather than returned, default =
|
sub_inplace |
Optional keyword arguments passed to |
Example:
rtnumber1:
fields: PHA_ROADNA
functions:
- function: regex_find
pattern: "\\b([1-9][0-9]*)\\b"
match_index: 0
group_index: 0
Function: regex_sub#
Parameter |
Value |
|---|---|
**kwargs |
Keyword arguments passed to |
Example:
rtename1en:
fields: PHA_ROADNA
functions:
- function: regex_sub
pattern: "\\b(No. [1-9][0-9]*)\\b"
repl: ""
Field Mapping Functions - Special Keys#
Process Separately#
process_separately is a special key which can be included with the mandatory field mapping keys (fields and
functions). When process_separately: True, multiple source attributes can be mapped to field mapping functions
which normally accept only a single source attribute.
The purpose of this special key is to allow multiple source attributes to be mapped to the same NRN attribute when the field mapping is not direct.
The output values of process_separately will be nested.
Example:
placename:
fields: [SPN_L_Place_Name, SPN_R_Place_Name]
process_separately: True
functions:
- function: map_values
lookup:
1: Aboujagane
2: Acadie Siding
3: Acadieville
...
Iterate Columns#
iterate_cols is a special key which can be included with the keys specific to each function. iterate_cols
accepts a list of integers representing the positional index of the source attributes listed by fields. When
populated, only the source attributes indicated by iterate_cols are processed by the defined field mapping
function. Source attributes not specified by iterate_cols will retain their values.
The purpose of this special key is to allow a chain where only some source attributes require additional processing
by certain field mapping functions.
Example:
l_stname_c:
fields: [L_Direction_Prefix, L_Type_Prefix, L_Article, L_Name_Body, L_Type_Suffix, L_Direction_Suffix]
functions:
- function: map_values
iterate_cols: [0, 5]
lookup:
1: North
2: South
3: East
4: West
- function: concatenate
columns: [dirprefix, strtypre, starticle, namebody, strtysuf, dirsuffix]
separator: " "
Field Domains#
When using any field mapping function which accepts a regular expression, the keyword domain_<dataset>_<attribute>
can be used to insert the restricted domain values of any NRN attribute into the expression, separated by the or
operator |.
Example (raw):
dirprefix:
fields: L_Directional_Prefix
functions:
- function: regex_find
pattern: "\\b(domain_strplaname_dirprefix)\\b(?!$)"
match_index: 0
group_index: 0
The above field mapping definition will be converted to:
dirprefix:
fields: L_Directional_Prefix
functions:
- function: regex_find
pattern: "\\b(None|North|South|East|West|Northwest|Northeast|Southwest|Southeast|Central|Centre)\\b(?!$)"
match_index: 0
group_index: 0
Note
Only a condensed list of domain values are shown in order to conserve space.
Nested Output#
Exclusive to the NRN dataset strplaname, following the complete field mapping process, if any output attributes are
populated by nested values, such as a list, all records within that dataset will be duplicated such that the first
nested value of each nested attribute becomes the actual attribute value for the first duplicated instance and the
second nested value of each nested attribute becomes the actual attribute value for the second duplicated instance.
This exclusive logic for NRN dataset strplaname allows for attributes with left- and right-side representation to
be assigned to a single NRN attribute.
Example:
placename: [SPN_L_Place_Name, SPN_R_Place_Name]
Address Segmentation#
The NRN conform process includes a special process to segment addresses contained within a Point dataset into
ranges. For address segmentation, no conform key exists and, instead, an additional key segment is included
within the data key and has the following raw structure:
segment:
address_fields:
street:
number:
suffix:
address_join_field:
fields:
separator:
roadseg_join_field:
fields:
separator:
This data structure contains 3 mandatory keys:
address_fieldsDefines how to extract address components from the source data. Only the basic attribute components of
street(street name),number(address number), andsuffix(address number suffix) are accepted. Acceptable values are:a) an attribute name or,b) aregex_subdictionary consisting of keysfield,pattern, andreplwhich will be passed tore.sub().c) aconcatenatedictionary consisting of keys defining the concatenation of attributes:fields: A list of attributes.separator: A delimiter used to concatenate the attributes.address_join_fieldAttribute of the address source used to join with NRN dataset
roadseg. Acceptable values are:a) an attribute name or,b) a dictionary consisting of keys defining the concatenation of address source attributes:fields: A list of address source attributes.separator: A delimiter used to concatenate the attributes.roadseg_join_fieldAttribute of NRN dataset
roadsegused to join with the address source. Acceptable values are:a) an attribute name or,b) a dictionary consisting of keys defining the concatenation of NRN datasetroadsegattributes:fields: A list of NRN datasetroadsegattributes.separator: A delimiter used to concatenate the attributes.
Output#
The output dataset will contain all addressing attributes of the NRN dataset addrange and will use the provided
attributes (address_join_field and roadseg_join_field) to be joined to whichever source dataset is mapped to
NRN dataset roadseg. Therefore, all addressing attributes of addrange can be used in the configuration file for
NRN dataset roadseg since they will exist on the source dataset prior to the execution of the field mapping process.
Examples#
Simple Example (source: Prince Edward Island):
segment:
address_fields:
street: street_nm
number: street_no
suffix:
address_join_field: street_nm
roadseg_join_field: street_nm
Advanced Example (source: Yukon):
segment:
address_fields:
street: street
number:
field: number
regex_sub:
pattern: "[^\\d]"
repl: ""
suffix:
field: number
regex_sub:
pattern: "\\d+"
repl: ""
address_join_field: street
roadseg_join_field:
fields: [dirprefix, strtypre, namebody, strtysuf, dirsuffix]
separator: " "